Presentation
What is Tolosa?
Section titled “What is Tolosa?”Tolosa (TOols Library for unstructured Ocean models and Surge Applications) is a free and open-source computational framework for simulating ocean and river dynamics on unstructured meshes using MPI parallelization and original numerical schemes. It is developed at IMT Toulouse (INSA/CNRS) in collaboration with SHOM, ICJ Lyon, LAMA Chambéry, and INRAE Grenoble.
Three Pillars
Section titled “Three Pillars”Mathematical Models
Phase-resolved ocean wave modeling via a novel Boussinesq-type model (hyperbolized Green-Naghdi equations) and an original wave breaking model based on enstrophy
Numerical Methods
Schemes on unstructured meshes for complex shorelines; global stability by entropy dissipation; compromise between accuracy, robustness, and performance
High Performance Computing
Written in modern Fortran 2008 with OOP features; CPU and GPU with MPI parallelization; GPU speedup up to ~11× over a CPU node (AMD MI300A, Adastra)
Design Philosophy
Section titled “Design Philosophy”Tolosa follows the KISS principle (Keep It Simple and Stupid), leveraging modern object-oriented programming features from the Fortran 2003 and 2008 standards. The codebase is lightweight and maintainable while delivering optimal computational efficiency.
Architecture
Section titled “Architecture”All Tolosa simulation codes are built on the shared Tolosa-lib library, which provides reusable structures and tools for mesh handling, MPI parallelization, I/O, and numerical utilities.
Simulation Codes
Section titled “Simulation Codes”Tolosa-lct
Boussinesq-type dispersive wave solver — phase-resolved coastal wave modeling, wave breaking with enstrophy, active wave generation
Tolosa-sw
Saint-Venant shallow-water solver — marine flooding, tides, storm surges with atmospheric and tidal forcing
Tolosa-euler
Two-phase Euler model — free-surface flow with ALE (Arbitrary Lagrangian-Eulerian) formulation
Supporting Components
Section titled “Supporting Components”Tolosa-lib
Core library: unstructured mesh handling, MPI domain decomposition, linear algebra, I/O (VTK, VTKHDF, Adios2, Tecplot, YAML)
PyTolosa
Python-based post-processing and visualization tool
Applications
Section titled “Applications”Operational Marine Flooding
SHOM and Météo France deploy Tolosa-sw for marine flooding warnings coupled with atmospheric pressure forecasts. A 5-day Atlantic prediction runs in 5 minutes on 640 CPU cores (2.6 M cell mesh).
Coastal Wave Modeling
Tolosa-lct handles large-scale phase-resolved simulations: Île de Ré (~11 M cells) and Saint-Malo (~16 M cells at 1 m coastal resolution) with JONSWAP spectral input.
Academic Research
Soliton gases (LEGI Grenoble), turbulence models for hydraulics (G. L. Richard, J.-P. Vila), surface tension in Saint-Venant (D. Bresch, C. Ruyer-Quil), wave-structure interactions.
HPC Performance
Section titled “HPC Performance”Benchmark on the Saint-Venant model (36 M cells, ~204 000 time steps, Jean-Zay and Adastra supercomputers):
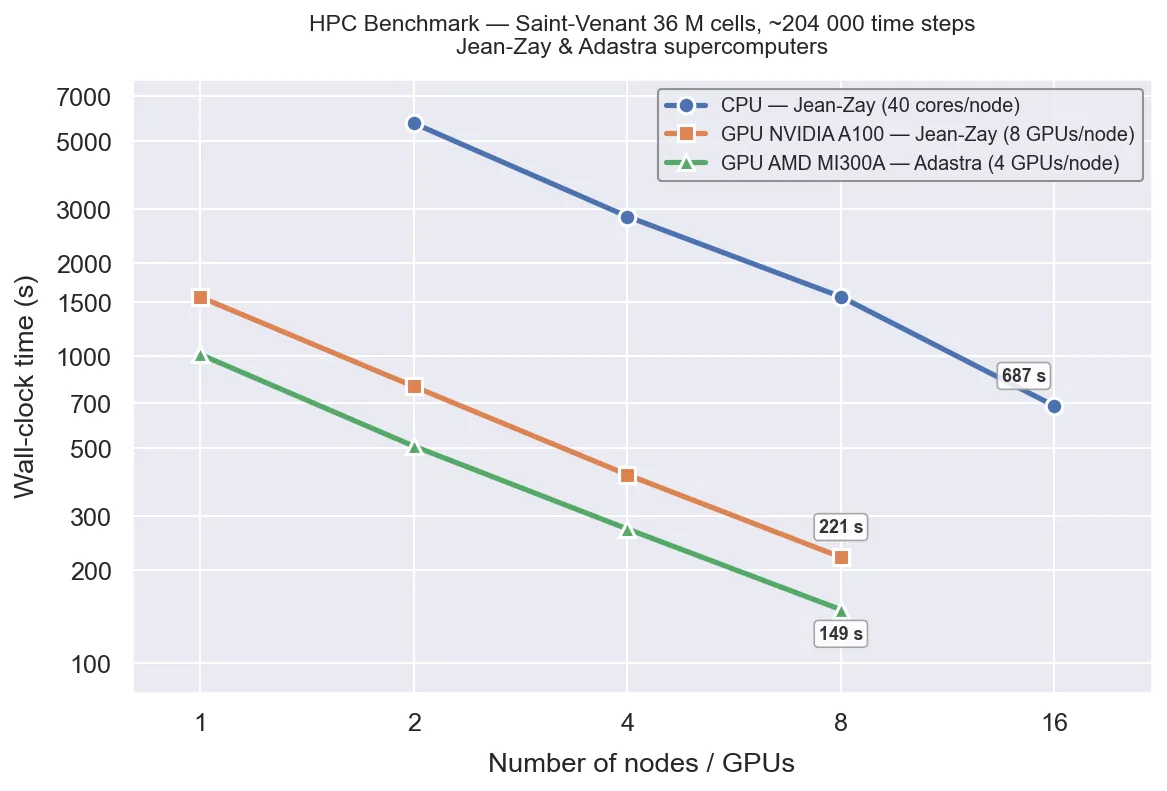
| Platform | Configuration | Time (s) |
|---|---|---|
| CPU — Jean-Zay (40 cores/node) | 2 nodes | 5726 |
| CPU — Jean-Zay (40 cores/node) | 4 nodes | 2845 |
| CPU — Jean-Zay (40 cores/node) | 8 nodes | 1558 |
| CPU — Jean-Zay (40 cores/node) | 16 nodes | 687 |
| GPU — NVIDIA A100 (Jean-Zay, 8 GPUs/node) | 1 GPU | 1555 |
| GPU — NVIDIA A100 (Jean-Zay, 8 GPUs/node) | 2 GPUs | 795 |
| GPU — NVIDIA A100 (Jean-Zay, 8 GPUs/node) | 4 GPUs | 410 |
| GPU — NVIDIA A100 (Jean-Zay, 8 GPUs/node) | 8 GPUs | 221 |
| GPU — AMD MI300A (Adastra, 4 GPUs/node) | 1 GPU | 1011 |
| GPU — AMD MI300A (Adastra, 4 GPUs/node) | 2 GPUs | 508 |
| GPU — AMD MI300A (Adastra, 4 GPUs/node) | 4 GPUs | 273 |
| GPU — AMD MI300A (Adastra, 4 GPUs/node) | 8 GPUs | 149 |
Both CPU and GPU architectures demonstrate good MPI parallel scaling. At 1 GPU: A100 is ~3.7× faster than 2 CPU nodes; MI300A is ~5.7× faster than 2 CPU nodes.